
Selected Publications
Please see my Google Scholar profile for a full list of publications.
📚 Data-Centric Computer Vision (Dataset Curation, Data Generation, Benchmarking)

MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
NeurIPS, 2024.

LDPose: Towards Inclusive Human Pose Estimation for Limb-Deficient Individuals in the Wild
ICCV, 2025.
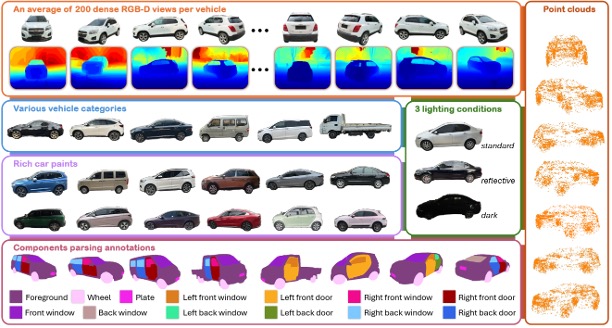
3RealCar: An in-the-wild RGB-D Car Dataset with 360-Degree Views
ICCV, 2025.

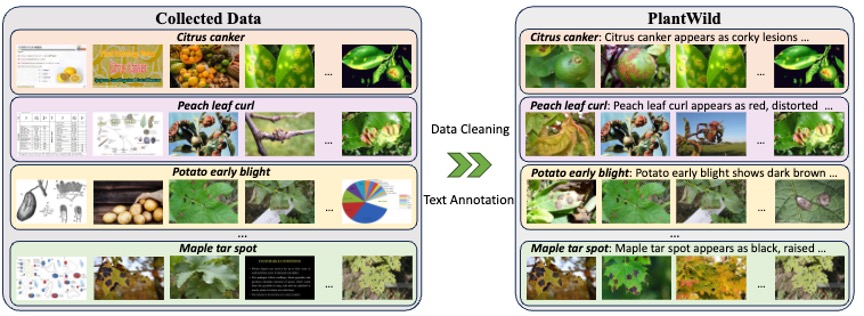
Plantseg: A Large-scale in-the-wild Dataset for Plant Disease Segmentation
Nature Scientific Data, 2026.
Benchmarking in-the-wild Multimodal Disease Recognition and a Versatile Baseline
ACM International Conference on Multimedia, 2024.
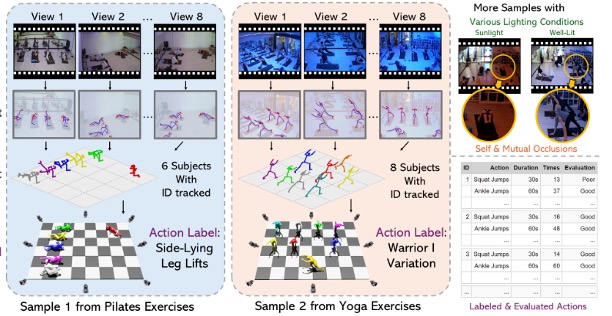
M3GYM: A Large-Scale Multimodal Multi-view Multi-person Pose Dataset for Fitness Activity Understanding in Real-world Settings
CVPR, 2025.
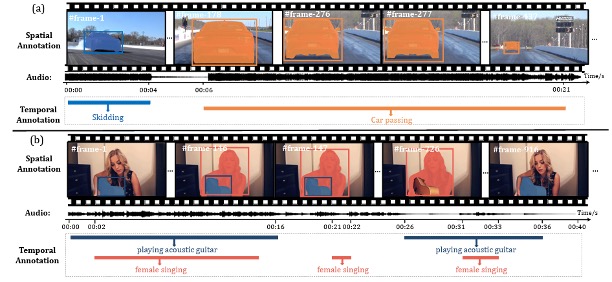
Benchmarking Audio-Visual Segmentation for Long-Untrimmed Videos
CVPR, 2024.
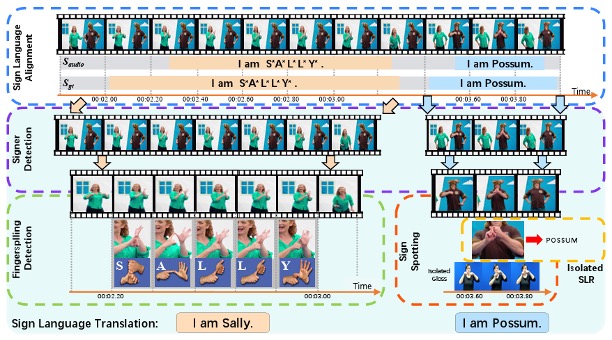
Auslan-daily: Australian Sign Language Translation for Daily Communication and News
NeurIPS, 2023.
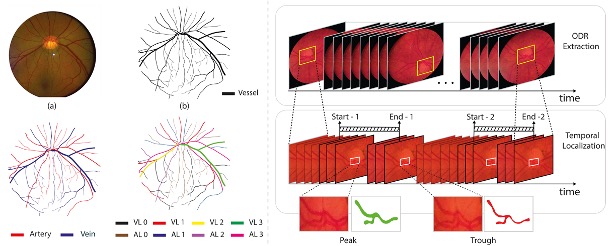
RVD: A Handheld Device-Based Fundus Video Dataset for Retinal Vessel Segmentation
NeurIPS, 2023. (Equal Contribution)

Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison
WACV, 2020. (Best Paper Honourable Mention Award)
📚 Human-Centric Visual Intelligence (Face, Body, Action, Emotion)
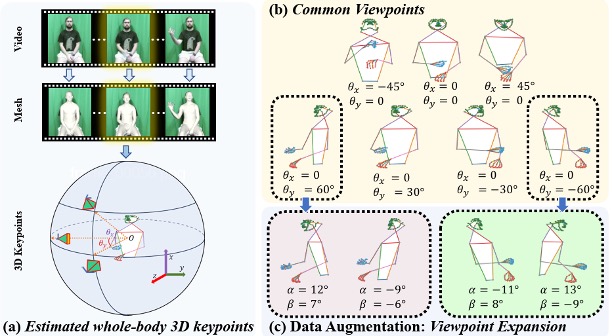
Cross-View Isolated Sign Language Recognition via View Synthesis and Feature Disentanglement
ICCV, 2025.
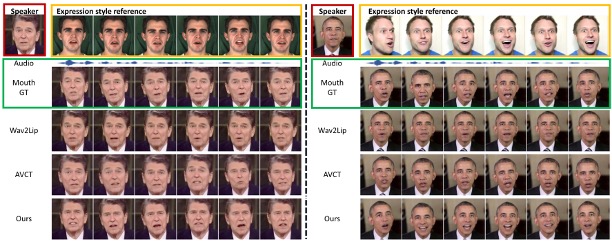
Styletalk++: A unified Framework for Controlling the Speaking Styles of Talking Heads
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
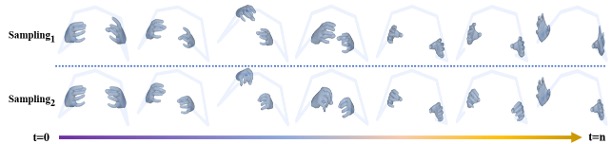
Diverse 3D Hand Gesture Prediction From Body Dynamics by Bilateral Hand Disentanglement
CVPR, 2023.

Transferring Cross-domain Knowledge for Video Sign Language Recognition
CVPR, 2020. (Nomination for Best Paper Award)
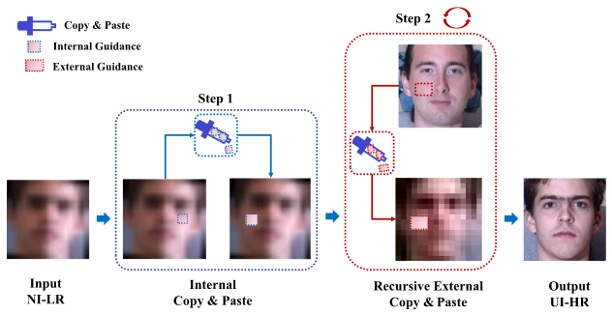
Copy and Paste GAN: Face Hallucination from Shaded Thumbnails
CVPR, 2020. (Oral)
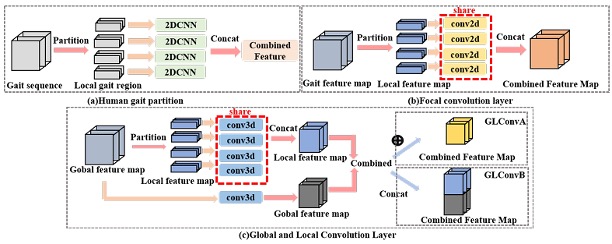
Gait Recognition via Effective Global-Local Feature Representation and Local Temporal Aggregation
ICCV, 2021.

Semantic Face Hallucination: Super-Resolving Very Low-Resolution Face Images with Supplementary Attributes
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.

Can We See More? Joint Frontalization and Hallucination of Unaligned Tiny Faces
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.

Hallucinating Very Low-Resolution Unaligned and Noisy Face Images by Transformative Discriminative Autoencoders
CVPR, 2017 (Spotlight).
📚 Foundation Models and Multi-modality Models (MLLM, VLM)
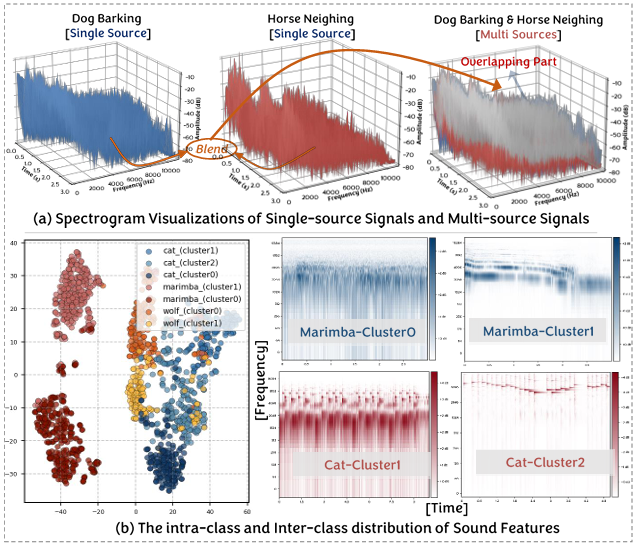
Dynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics
CVPR, 2025.
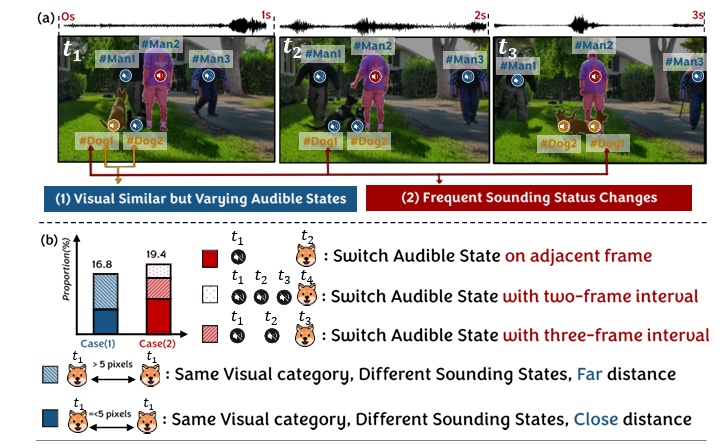
Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment
CVPR, 2025.
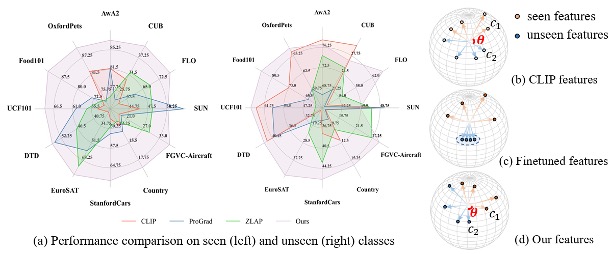
TPR: Topology-preserving Reservoirs for Generalized Zero-shot Learning
NeurIPS, 2024.

MDAM3: A Misinformation Detection and Analysis Framework for Multitype Multimodal Media
ACM on Web Conference (WWW), 2025.

Blind Bitstream-corrupted Video Recovery via Metadata-guided Diffusion Model
CVPR, 2025.
📚 3D Vision and Augmented Reality (3D Reconstruction, 3D Understanding)
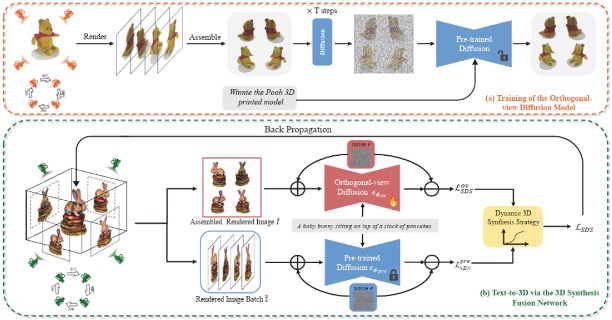
Efficientdreamer: High-fidelity and robust 3d creation via orthogonal-view diffusion priors
CVPR, 2024.
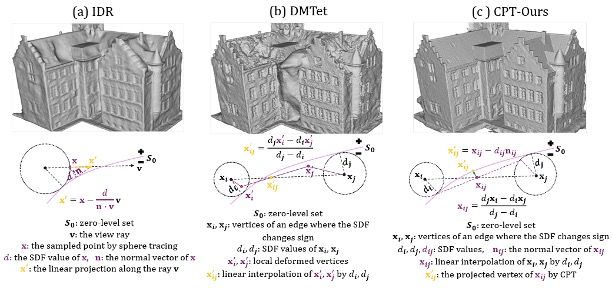
CPT-VR: Improving Surface Rendering via Closest Point Transform with View-Reflection Appearance
ECCV, 2024.
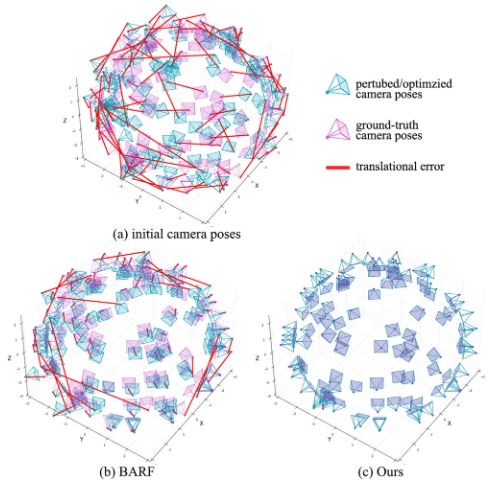
CBARF: Cascaded Bundle-Adjusting Neural Radiance Fields From Imperfect Camera Poses
IEEE Transactions on Multimedia, 2024.
FreeAvatar:Robust 3D Facial Animation Transfer by Learning an Expression Foundation Model
SIGGRAPH Asia, 2024.
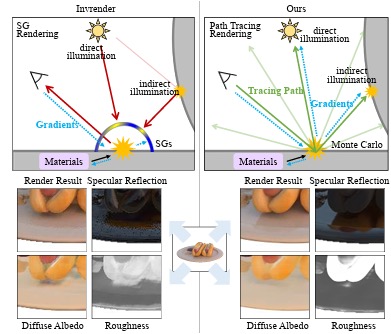
NeFII: Inverse Rendering for Reflectance Decomposition with Near-Field Indirect Illumination
CVPR, 2023.
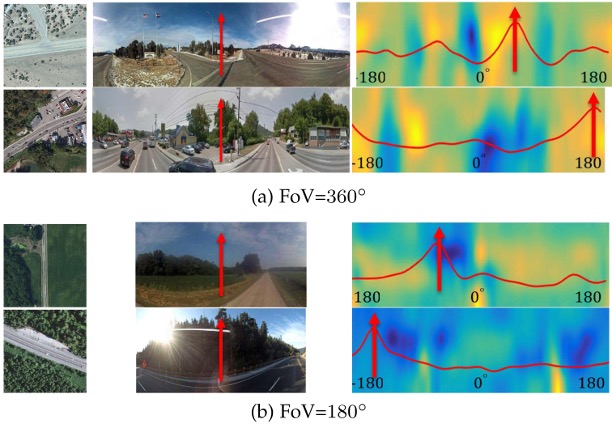
Accurate 3-DoF Camera Geo-Localization via Ground-to-Satellite Image Matching
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. (Equal Contribution)
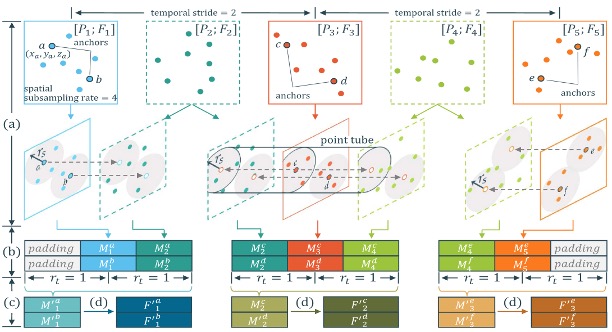
Deep Hierarchical Representation of Point Cloud Videos via Spatio-Temporal Decomposition
IEEE Trans. Pattern Analysis and Machine Intelligence, 2022.
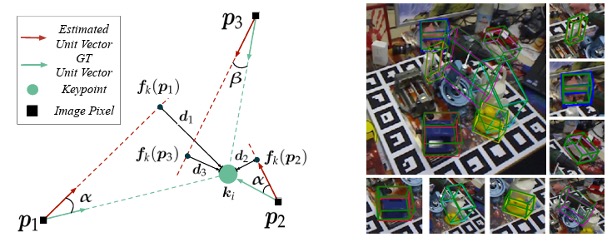
6DoF Object Pose Estimation via Differentiable Proxy Voting Regularizer
BMVC, 2020. (Oral)
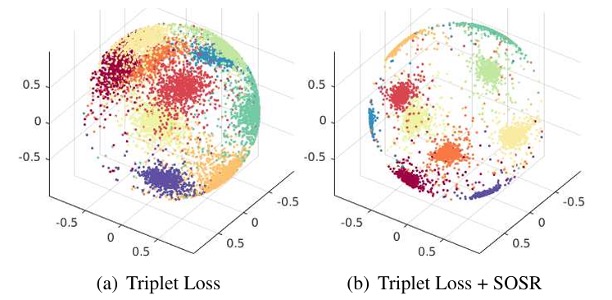
SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
CVPR, 2019. (Oral)